Chapter 4⚓︎
单周期CPU⚓︎
Implementation Overview⚓︎
-
1st: identical
-
从内存中取出指令
-
解码,(读寄存器)
-
2nd:依据指令类型,进行内存访问/计算/分支
-
ALU计算
- 访问内存,读写
- 修改PC
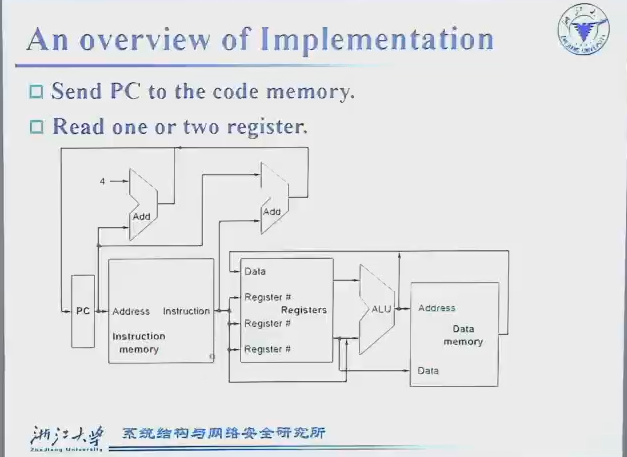
-
PC:寄存器,电脑运行指令的指针
-
Instruction Memory:存储指令,用来读取
-
Registers:寄存器读出/写入
-
Data Memory:更大的内存
-
ALUs
-
右下:用于寄存器加减等操作
- 左上:正常运行,
pc=pc+4 -
右上:非正常运行(如jal),偏移值来自指令
-
多处数据汇流:需要mux
-
下:ALU操作数可能是与立即数或者寄存器;寄存器出来的值(还没懂,待研究!!!)
- 中:指令可能只是算数运算,结果从ALU产生,也可能是如
ld t1, 0(t2)之类从 Data Memory产出 - 上:是否跳转决定PC的改变量
图上是数据流向的示意图datapath,但读还是写之类需要另外一套控制系统,如下图蓝色部分
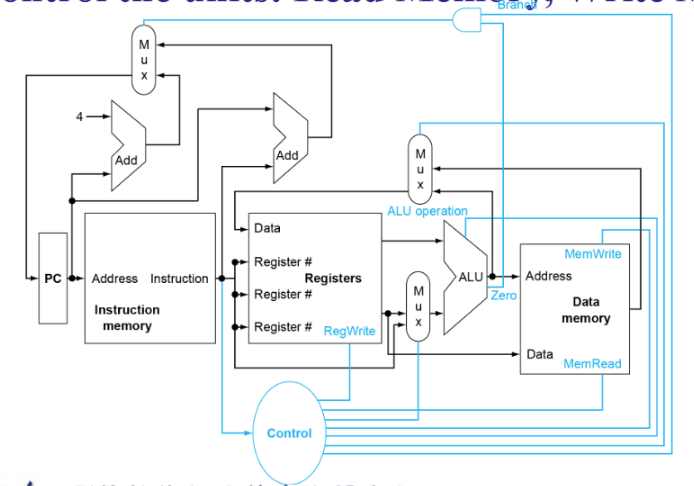
Datapath⚓︎
部件⚓︎
-
组合逻辑:ALU、Adder、Multiplexer
-
时序逻辑:Registers、Register files、存储器
-
Registers
- 写使能 Write Enable : 置为1且有效时钟边沿到来时修改数据输出为输入值
- Register files:32个Register
- 32位输出端口 busA busB & 32位输入端口 busW
- 5位输入端口 RW RA RB
- Clk & Write Enable
- 读操作:RA 作为地址选择的数据输出到 busA ; RB \(\Rightarrow\) busB,不受 clk 限制
- 写操作:当 Write Enable 为1时 RW 作为地址选择的寄存器写入 busW 的数据,受 clk 限制
-
存储器:对应示意图中 Data Memory 的部分
- 输入输出端口 DataIn & DataOut
- 地址线 Address
- Clk & Write Enable
- 读操作: Address 处数据输出到 DataOut
- 写操作:当Write Enable为1且时钟边缘有效时向 Address 处写 DataIn
-
Summary:三个部件在读功能时不受 clk 限制,相当于组合逻辑部件,但写操作都要在 clk 有效边缘
Q :非阻塞和阻塞赋值?
A :非阻塞等式右边的值统一评估完一起赋值;阻塞赋值是逐条进行,以这组代码为例
always @ (posedge clk)begin
c<=1;
b<=c;
a<=b;
end
上文是非阻塞赋值,因而c = 1需要两个时钟才能给到a
always @ (posedge clk)begin
c=1;
b=c;
a=b;
end
这是阻塞赋值,运行是逐行的,因此在一个周期内就能完成 a=b=c=1 的任务
各类操作对应的 Data path 和 Control 情况⚓︎
完整结构图
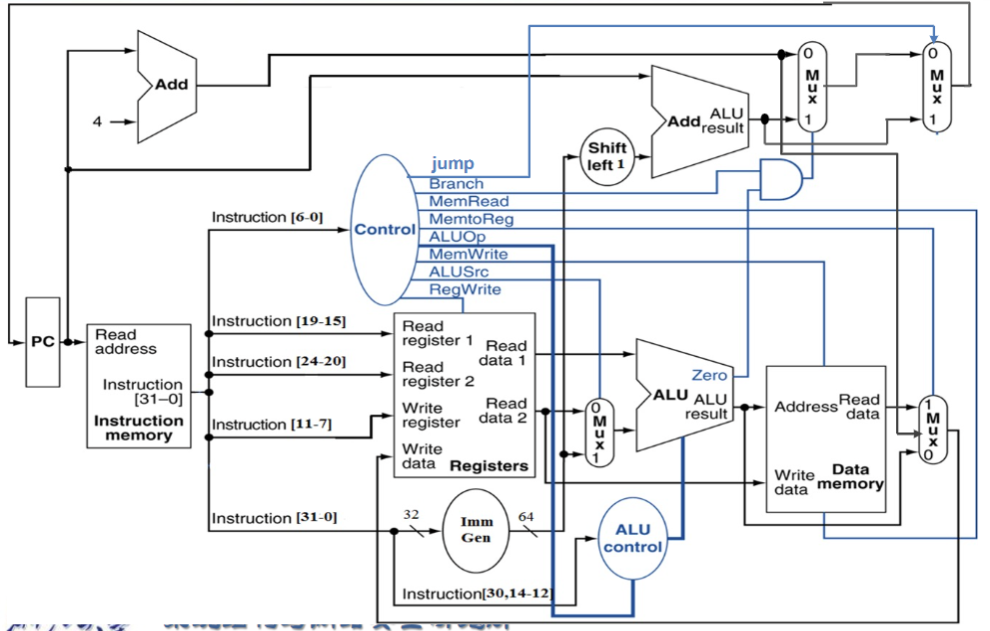
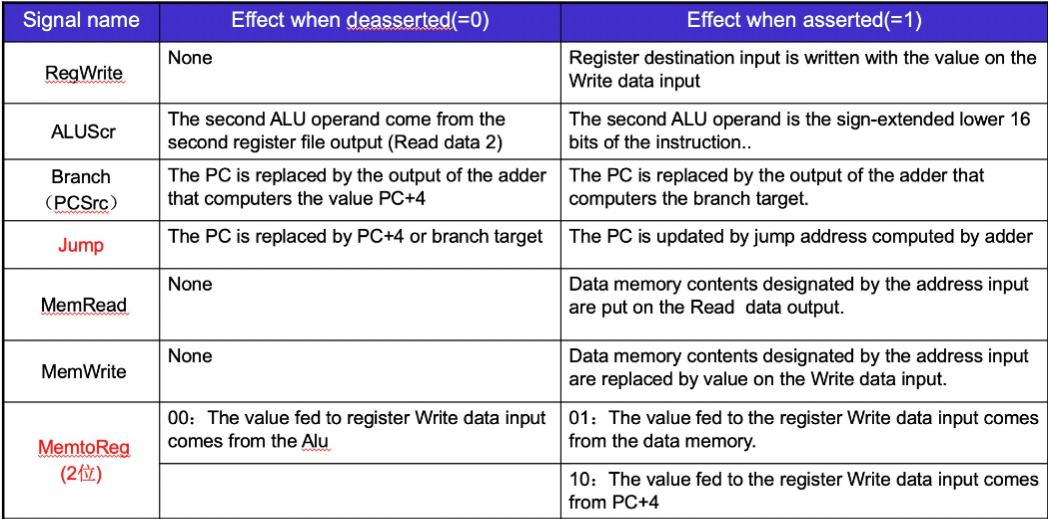
Control信号的作用
R型⚓︎
- Instruction 流向 Reg1 和 Reg2 和 Wreg , Reg1 与 Reg2 进入 ALU ,ALU result 直接从 Mux 流向 Reg 的 Write Data
- RegWrite 1, ALUSrc 0, ALU operation 取决于具体指令, MemWrite 和 MemRead 0,MemtoReg 00, PCSrc 0
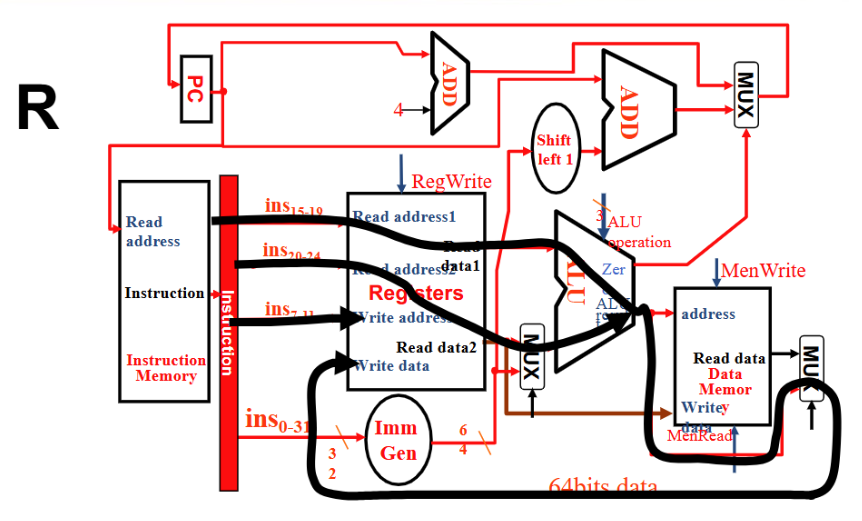
I 型⚓︎
- Instruction 流向 Reg1 和 WReg 及 Imm Gen , Imm Gen 和 Reg1 进入 ALU ,结果输入 Memory address , 再从 MUX 流回 Reg Write Data.
- RegWrite 1, ALUSrc 1, ALU operation加, MemWrite 0, MemRead 1, MemtoReg 01, PCSrc 0
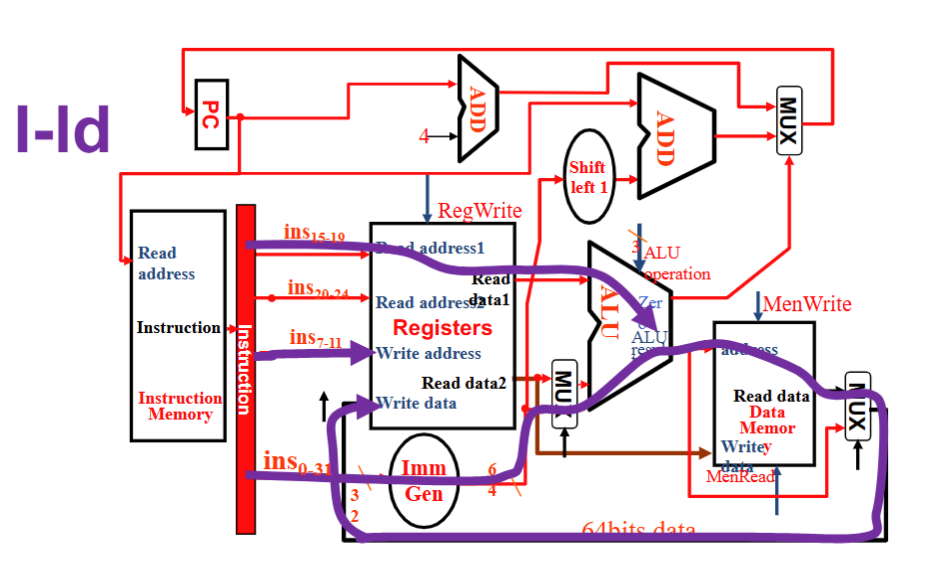
S 型⚓︎
- Instruction 流向 Reg1, Reg2 和 Imm Gen, Imm Gen 和 Reg1 进入 ALU,结果输入 Memory address, Reg2 流向 Memory Write Data
- RegWrite 0, ALUSrc 1, ALU operation加, MemWrite 1, MemRead 0, MemtoReg 无所谓 , PCSrc 0
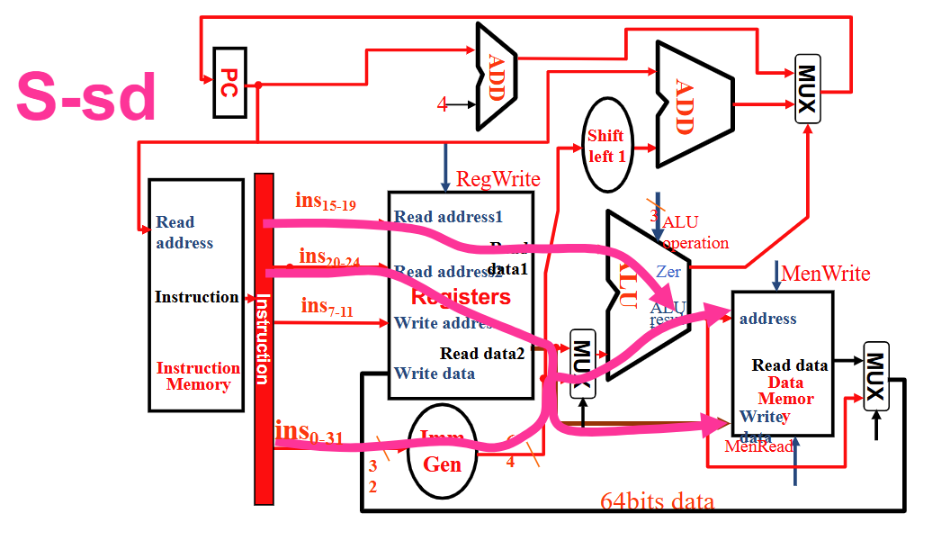
SB 型⚓︎
- Instruction 流向 Reg1, Reg2 和 Imm Gen,Reg1 和 Reg2 流入 ALU , ALU 的zero 流向顶上的 MUX, Imm Gen 流向 PC 的一个加法器
- RegWrite 0, ALUSrc 0, ALU operation减, MemWrite 0, MemRead 0, MemtoReg 无所谓, PCSrc 由 ALU 的 zero 给出
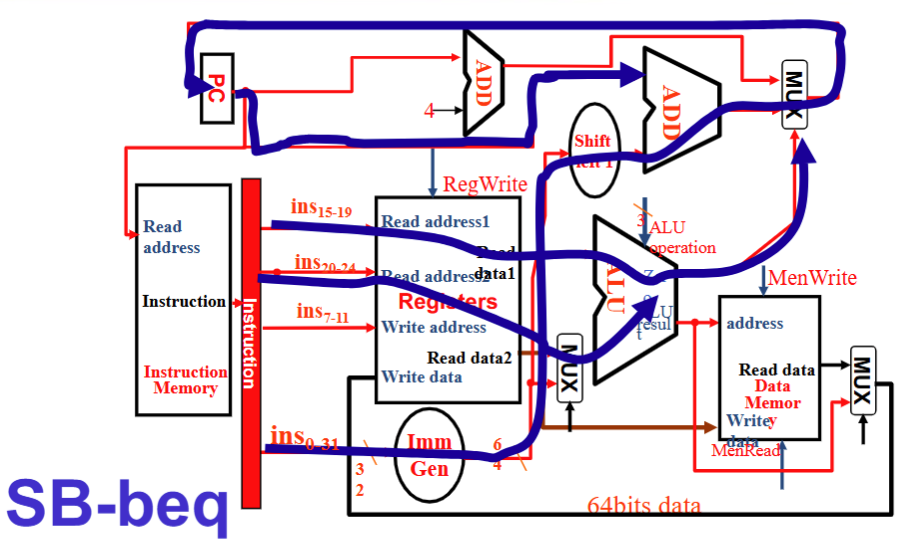
J 型⚓︎
- Instruction 流向 Imm Gen 和 WReg , Imm Gen 流向 Shift left1 从而进入PC的加法器, PC+4 汇入 Data Memory 右边的 MUX 再到 Reg Write Data
- RegWrite 1, ALUSrc 无所谓, ALU operation 无所谓, MemWrite 0, MemRead 0, MemtoReg 10 , PCSrc 1
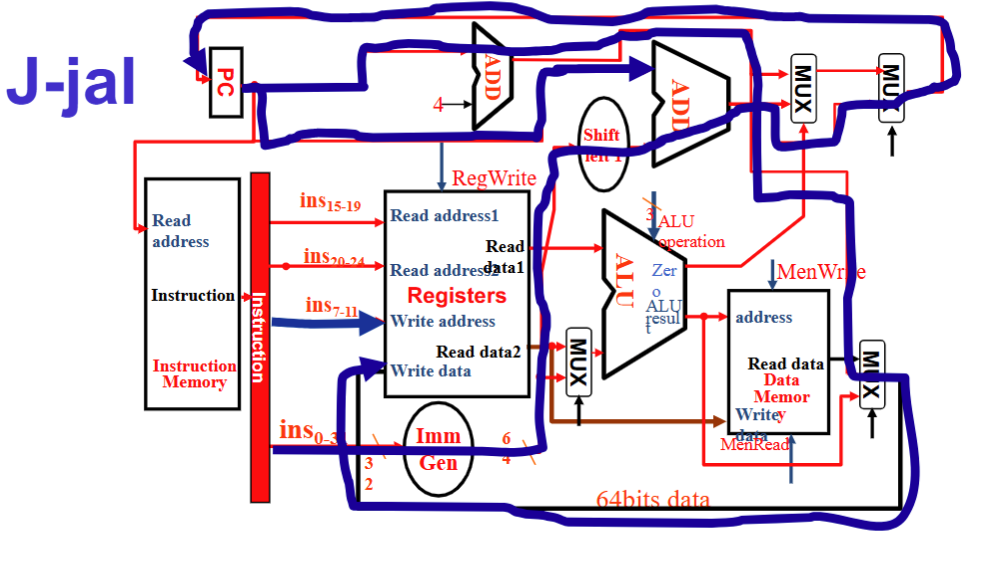
汇总:Control信号⚓︎
main control
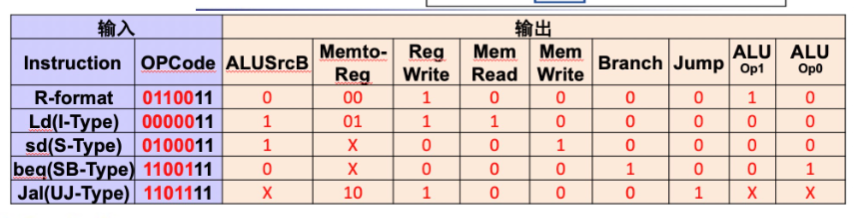
ALU control
Pipeline⚓︎
理论基础⚓︎
Five stages⚓︎
- IF : Instruction fetch from memory
- ID : Instruction decode & register read (同时进行)
- EX : Execute operation or calculate address
- MEM : Access memory operand
- WB : Write result back to register
不是所有指令都五步齐全,但是那一步还是要走
流水线处理 \(\Rightarrow\) CPI=1
存在问题⚓︎
数据竞争:相邻两指令用到同寄存器,存在依赖关系
\(\Rightarrow\) 插入 stall
- 需要对一段有依赖关系的代码算总时钟周期,能把依赖关系消除掉
\(\Rightarrow\) 旁路(bypass)过来(算完了马上取出来用,不走流程)
控制竞争:比如前一条指令是跳转,那么后一条指令执行什么取决于前一条的结果
\(\Rightarrow\) Branch Prediction
预测是否跳转(基于普遍历史经验预测),预测错误再插入stall
实现⚓︎
Datapath⚓︎
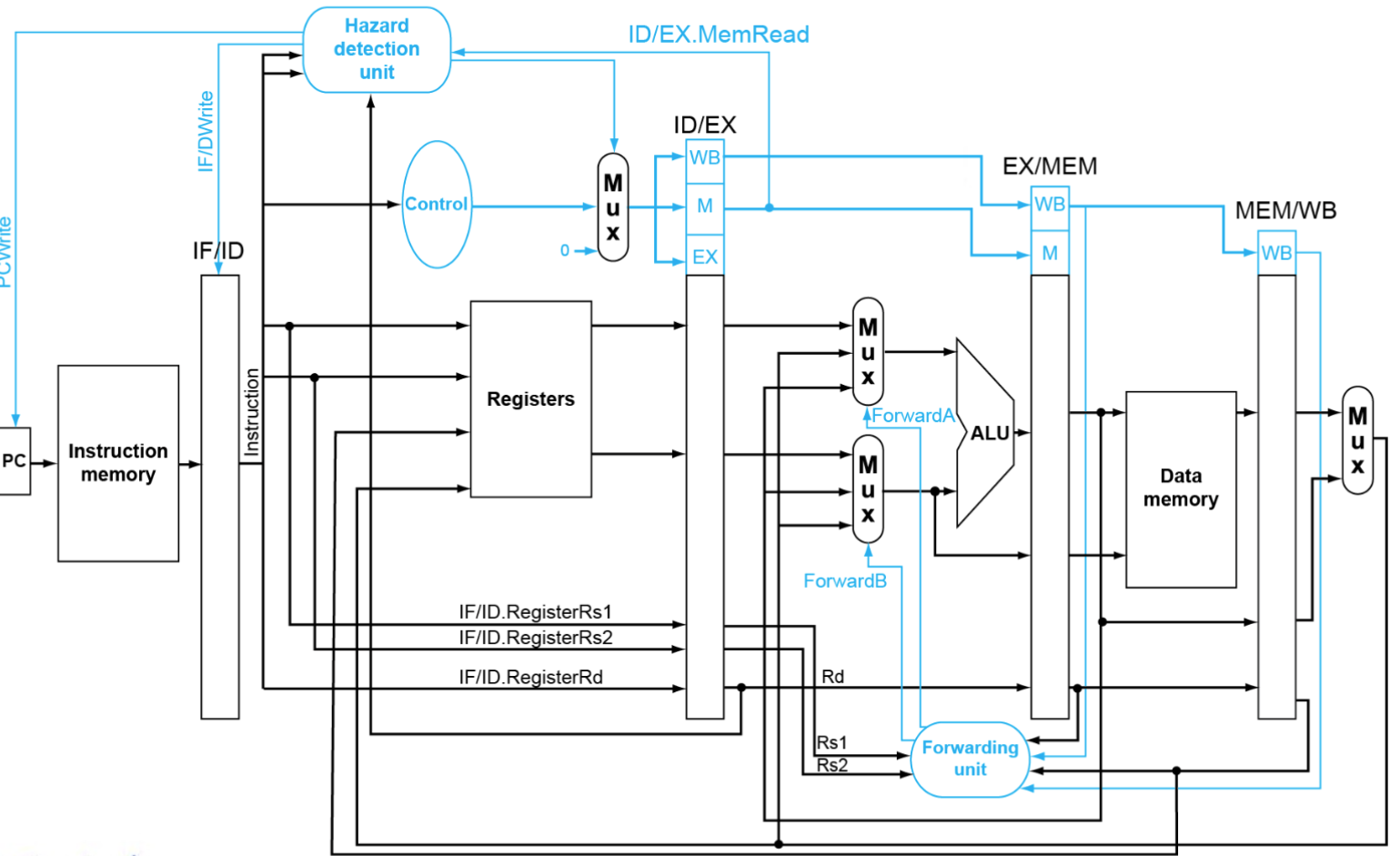
- 每层之间加寄存器,把结果存下来以为下一条指令做缓冲
- 以ld指令为例:直接使用上述设计最后写回的地址出问题了 \(\Rightarrow\) Write address(后面要用到的一切信号) 跟着逐级移动(不能直接跳层否则流程出问题)
Control⚓︎
- IF/ID解码指令,同单周期
- 后面边传边用边丢
Hazard⚓︎
Data Hazards⚓︎
- Detect

注意若 Rd 是 x0 就没必要了
若前一条指令是 ld 则无法旁路处理
ID/EX.MemRead and
((ID/EX.RegisterRd= IF/ID.RegisterRs1) or (ID/EX.RegisterRd=IF/ID.RegisterRs2))
-
Solve
-
bypath
一般可以从EX/MEM,MEM/WB旁路到ID/EX,因此需要设置一个选择器控制从哪里旁路(处理 Double Data Hazard)
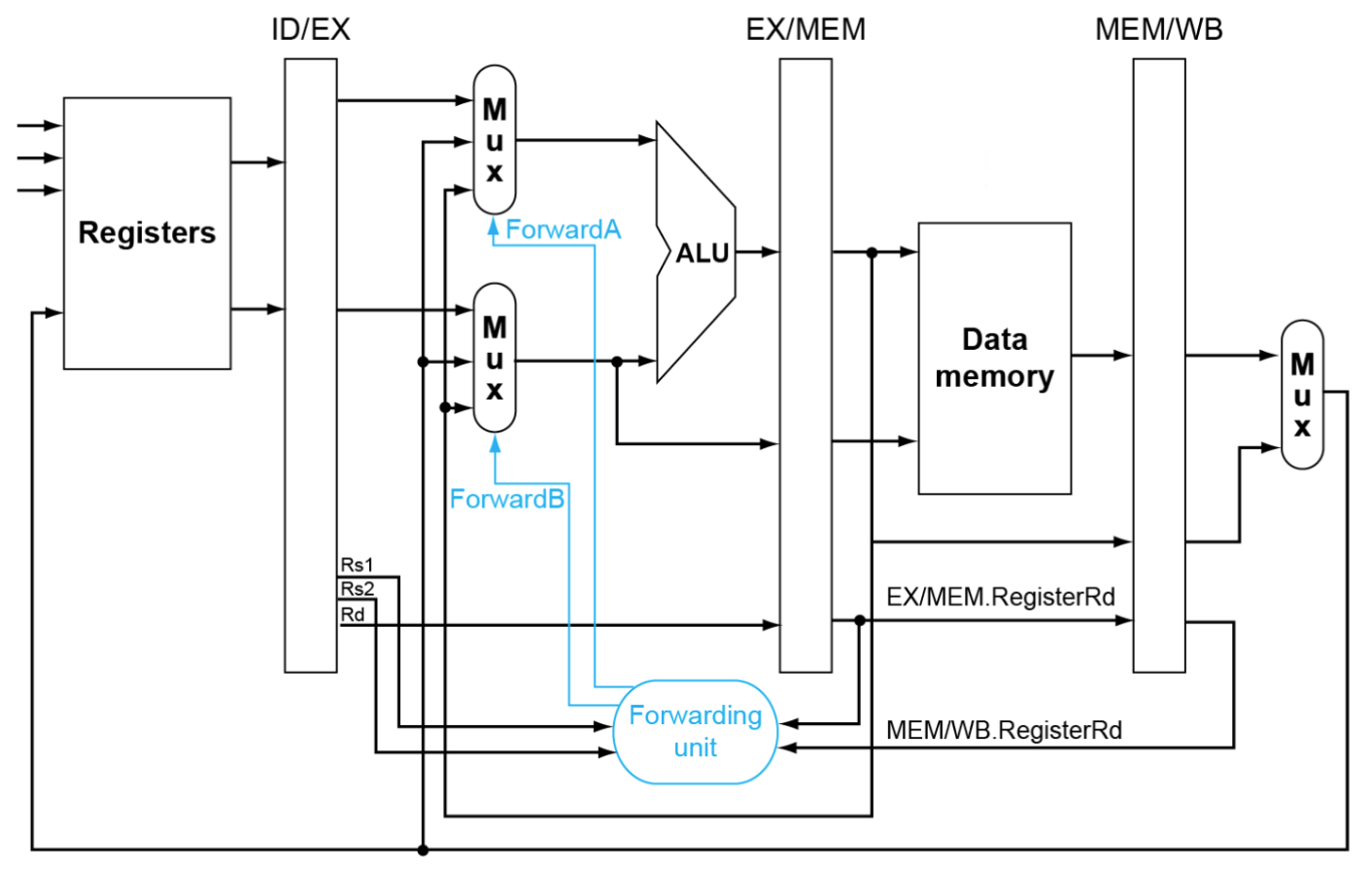
其中FowardA的信号对应选择方式如下,FowardB同理
if (MEM/WB.RegWrite and (MEM/WB.RegisterRd≠ 0) and not(EX/MEM.RegWrite and (EX/MEM.RegisterRd≠ 0) and (EX/MEM.RegisterRd=ID/EX.RegisterRs1)) and (MEM/WB.RegisterRd= ID/EX.RegisterRs1)) ForwardA= 01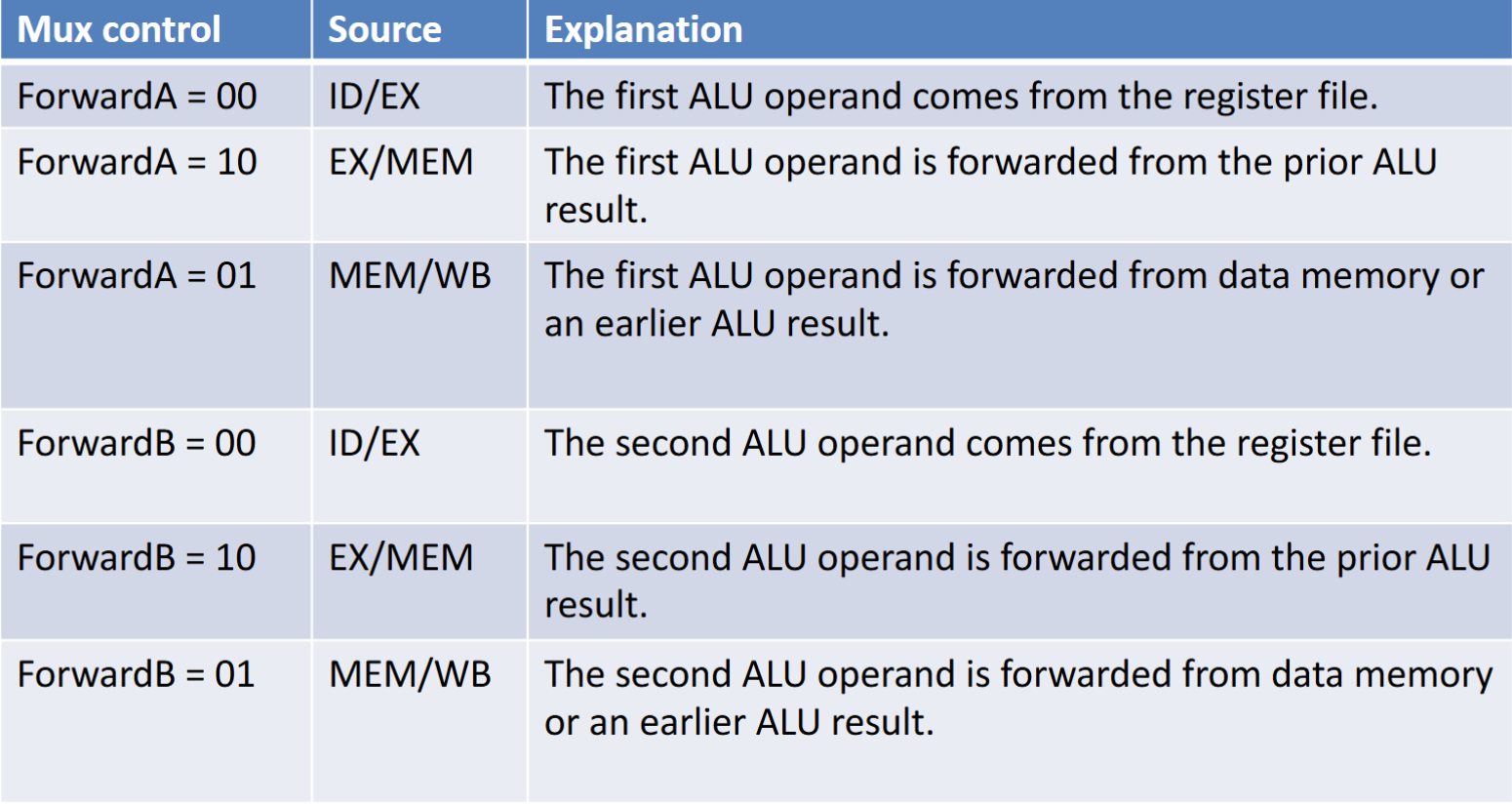
-
bubble
- 前一条指令是
ld,无法直接旁路,插入一个 bubble 可以从 MEM 旁路到 EX(Load-Use Hazard) - 强制清空 EX 到 WB 的所有 ( do nop )
- 只需要:控制信号置零(新增一个 Mux 用于控制)
- 阻止 PC 和 IF/ID 的更新(新增 Hazard detection unit 用于处理)
- 前一条指令是
Branch Hazards⚓︎
使用 Predictor 预测行为
- 1b :与上次跳转结果相同,索引与该指令PC相同
- 缺点:在双重循环的内层跳出循环和重进循环时会错两次
- 2b :增加一次的容错
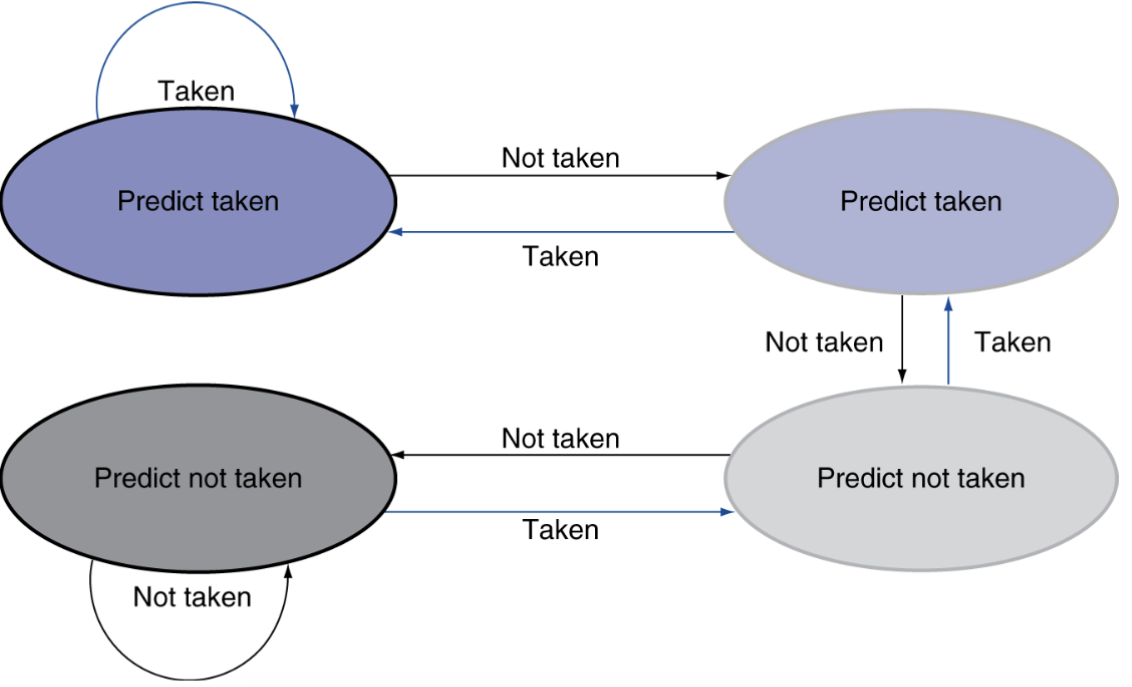
但是计算 PC 仍然会浪费一个周期
- 预存储好 PC 跳转的值
- 缺点:空间不够啊
- sol :存最近的
Instruction-Level Parallelism(ILP)⚓︎
- Multiple issue (多发)
-
CPI<1 ,所以改用 IPC 衡量效率
-
指令的依赖关系会使得实际 IPC 小于理论
-
Static Multiple issue
例如:每次同时处理一个ALU/branch+一个load/store指令
- 需要额外的寄存器,额外的ALU(只用加法就行)
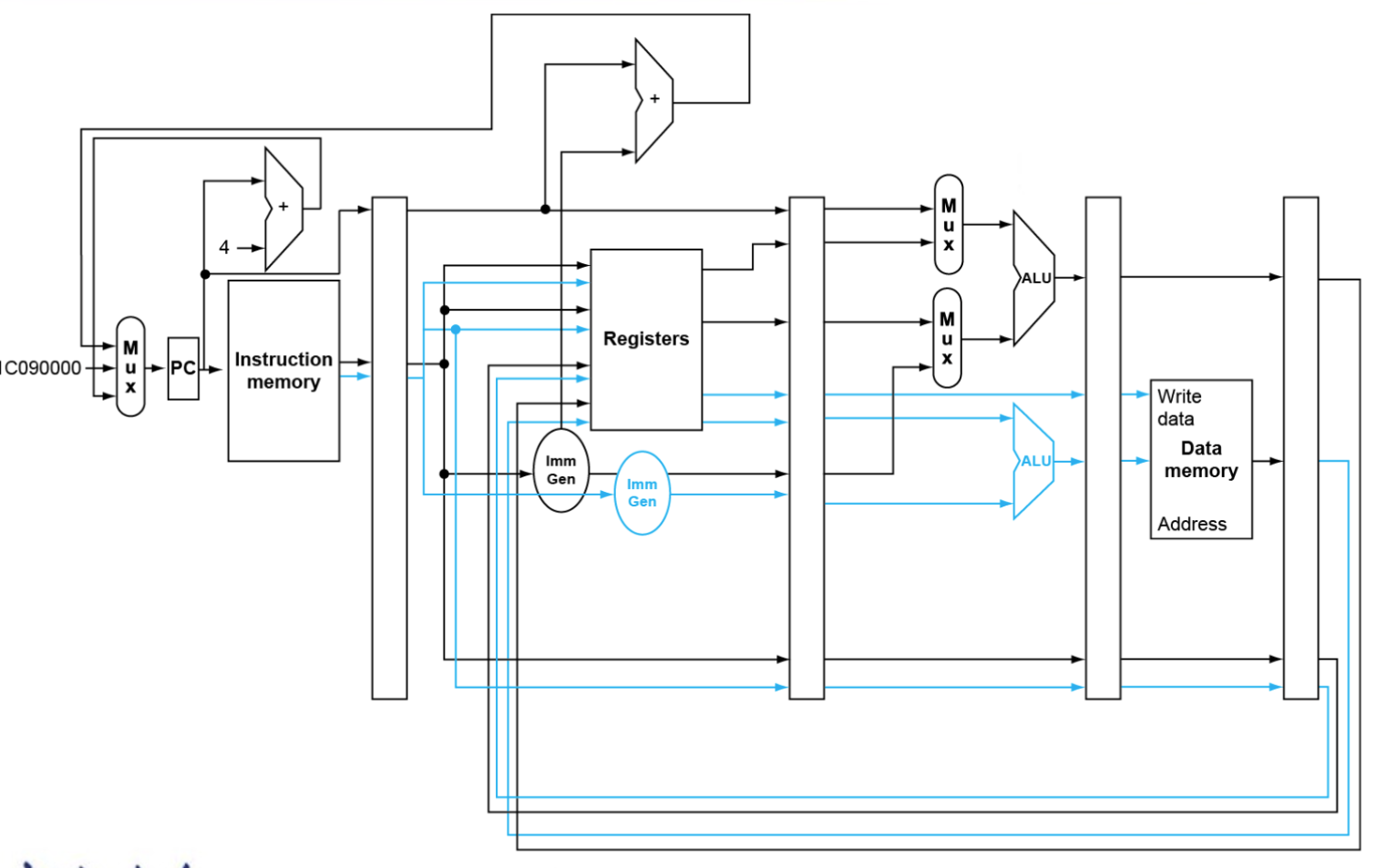
- 存在问题:遇到依赖差不多废了
例如

IPC只有1.25
- 处理方法: Loop Unrolling (编译器实现)
上图的循环可以几次循环捆在一起展开,让并行性提高
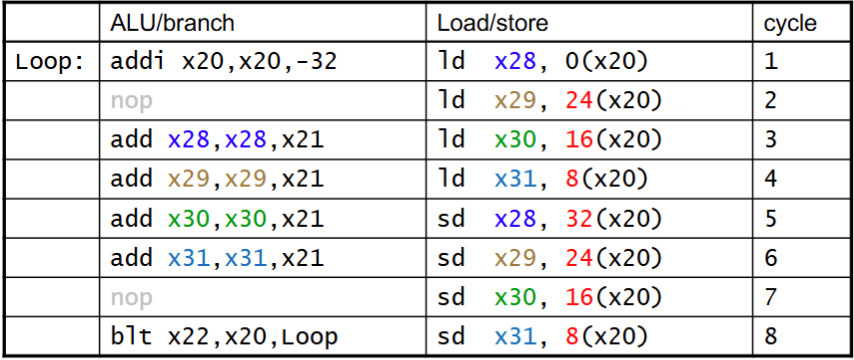
IPC提高到1.75
可以以这个例子理解
for(int i = 0; i < 20; ++i) a[i] += 5;Loop Unrolling后
for(int i = 0; i < 20; i+=4){ a[i]+=5; a[i+1]+=5; a[i+2]+=5; a[i+3]+=5; }a[i]+=5的过程改成RISC-V需要先ld再add再sd,改写后可以先全部ld再全部add再全部sd,冲突化解。 -
Dynamic Multiple issue
- "Superscalar" processors
- CPU自行决定处理几条指令(在避免hazards的前提下)
- 不需要编译器(虽然编译器可能有用)
- \(\Rightarrow\) 可以支持乱序执行,结果依然顺序写入寄存器/Memory
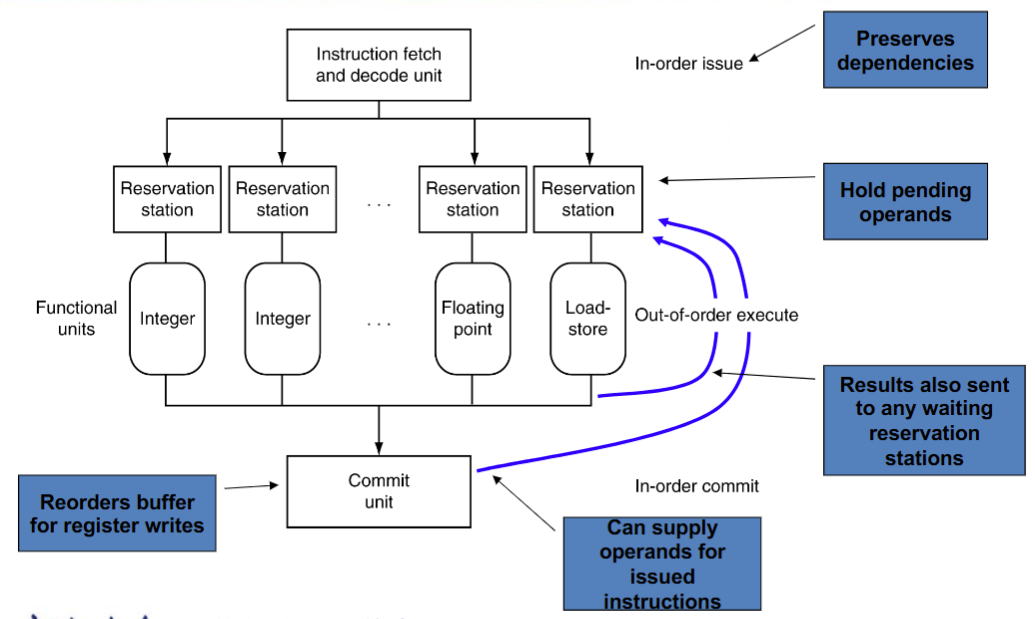
- 原因:编译器不总是理解何时有stall, 对branch结果了解不够实时,不专精于本指令集等
-
Register Renaming
- 解决指令在流水线中使用相同寄存器导致的冲突
- 如果操作数可用了就从 register file 或者 reorder buffer 放到 reservation station 去
- 否则后续由功能函数 直接提供到 reservation station,不经由寄存器
-
Speculation
- branch : 预测结果并依据预测结果继续算,但是直到 branch 的结果出来再确定计算结果要不要
- Load : 预测地址、Load的值、 bypass处理等。同样等到 speculation 被确认后再 commit
异常与中断⚓︎
- 不可预测事件(例如溢出、不合法指令等)
- 外部导致的
单周期的处理⚓︎
流水线的处理⚓︎
- 视为一种特殊的hazard
- 完成前面的操作,后面的操作及本操作的下一步即刻终止(flush)
- 更改 SEPC,SCAUSE 等,跳转到处理程序
问题:若同时存在多条指令出错
- sol 1 : 在最先一条指令报错,把后面的指令flush掉("precise exceptions")软件压力小硬件压力大
- 但是在乱序处理等频发的复杂流水线不好用
- sol 2 : 遇到问题报错,剩下交给软件("Imprecise exceptions")软件压力大硬件压力小