Chapter 2⚓︎
2 key principles
-
Instruction are represented as numbers.
-
Programs can be stored in memory to be read or written just like numbers.
指令集概览⚓︎
-
指令的Format决定了指令的结构
-
RISC-V指令集

- R型:操作全寄存器
- I型:两个寄存器,一个立即数
- S型:两个寄存器,一个立即数(被腰斩了)
- SB型:分支结构,与S型大体相似
- SB指令的imm[4:1,11]的安排是为了与S对齐
没有imm[0],很神奇吧,imm[12]是符号位拓展,默认第零位是0
- SB指令的imm[4:1,11]的安排是为了与S对齐
-
MIPS指令集

在一切开始之前...
- 称 32 bit 为一个 word ,而 64 bit 为一个 double word
- RISC-V 有 32 个寄存器,在课程标准下可以认为它们是 64 位的,但是实验中我们实现是32位的CPU,不要混淆。另外部分寄存器是被系统预留好的,如果不是题目要求最好别用。
- 虽然寄存器是 64 位的,但是每条指令都是 32 位的,在上面的 format 表格也可以看到
操作⚓︎
-
部分 R 型与 I 型:算数操作
-
One operation per instruction
-
3 variables(2 src+1 dest) ,如果是 R 型,则都是寄存器
例如:
- add dest src1 src2 (dest = src1 + src2)
- sub dest src1 src2 (dest = src1-src2)
-
I型的算数操作,在格式上将 src2 替换成相应立即数即可
-
示例:
A[12]=h+A[8],h在x21,A基址x22ld x9, 64(x22) add x9, x21,x9 sd 72(x22), x9ld是load double word,64(x22)指A[8],即数字部分是相对基址的偏移量(以字节为单位) -
示例:
h=h+55addi x9 x9 55 -
Byte/Halfword/Word Operations
寄存器都是64位不变的,因而即使只读回来一个 B 也要补全成 8B 。
- 在
lb,lh,lw指令时用符号位扩展 - 在
lbu,lhu,lwu指令时用0扩展
- 在
-
-
S型与部分I型:内存访问
-
只有读写两种操作
-
按byte操作
-
RISC-V是Little Endian(更低位的byte放在更小的地址)(Big Endian反之)
-
RISC-V不要求Memory Alignment
-
对齐:存储为0到3,4到7等,起始地址是4的倍数不会跨byte
-
-
部分R和I型:Logical Operations
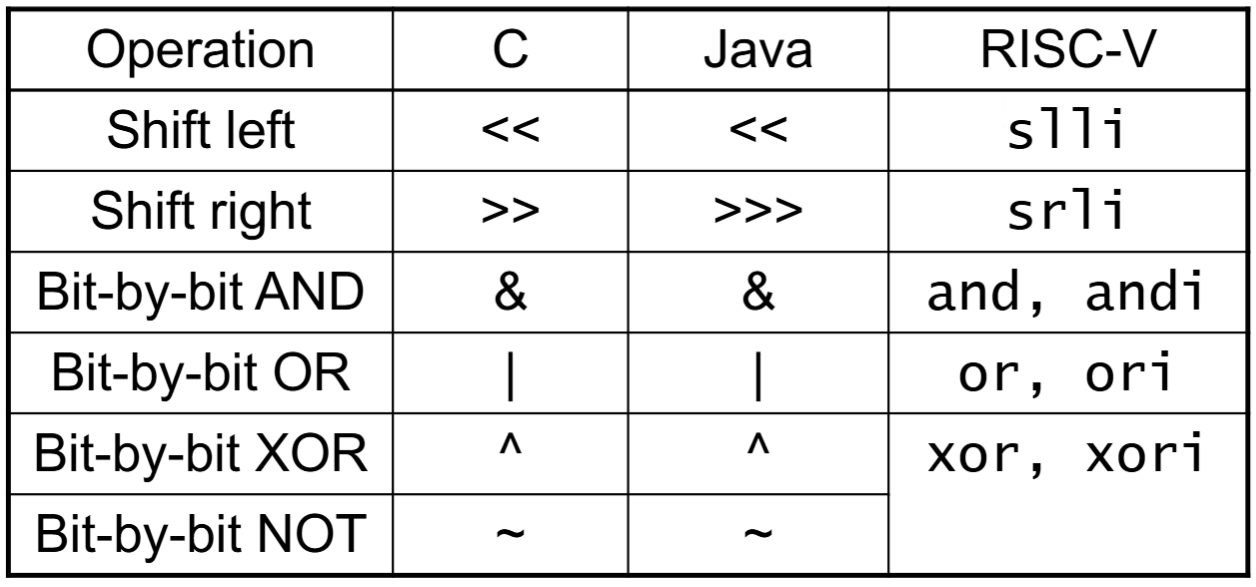
按位取反是不需要的(与全一取异或)
- Shift Operations : I format
- 补充:也存在 R 型的,但是只采用 rs2 的低五位作为位移量(至少实验中实现如此),而I型中由于相应立即数高位是 function6,所以最后有效的也只有五位。
- 位移操作存在逻辑和算数两种版本,区别在于扩展是补0还是符号位
- AND Operations & OR Operations & XOR Operations: R format
- Shift Operations : I format
-
SB型:Conditional Operations & Loop
-
beq : 相等则执行;bne : 不等则执行
beq x21,x22,L1,其中L1指代一个指令,值为那条指令与本指令的相对位置。 -
slt : 以
slt x5, x19, x20为例,若 \(x_{19}<x_{20}\) 则 \(x_5\) 为1 -
blt : 若 \(rs_1<rs_2\) 则跳转;bge : 若 \(rs_1\ge rs_2\) 则跳转
- 以及相应的unsigned形式bltu,bgeu
-
SB指令的立即数处理

-
循环的写法( g ~ k对应x20 ~ x24, base A[i] 存在 x25)
例一:
do{ g = g + A[i]; i = i + j; }while(i!=h);LOOP: slli x10,x22,3 #按字节数A[i]相对于A的偏移量 add x10,x10,x25 #x10存储A[i]的地址 ld x19 ,0(x10) #x19存储A[i]的值 add x20 x20 x19 add x22,x22,x23 bne x22,x21,LOOP例二:
while(A[i] == k) i+=1;LOOP: slli x10,x22,3 add x10,x10,x25 ld x9,0(x10) bne x9,x24,EXIT addi x22,x22,1 beq x0,x0,LOOP EXIT:....Q:LOOP的值为多少? A:相对调用语句
beq x0,x0,LOOP的偏移量,即 -5*4=-20 -
使用 jump address table 实现switch
假设 f ~ k 对应 x20 ~ x25, x6 存储 jump address table 的基址,则对应汇编代码如下
blt x25, x0, Exit # test if k < 0 bge x25, x5, Exit # if k >= 4, go to Exit slli x7, x25, 3 # temp reg x7 = 8 * k (0<=k<=3) add x7, x7, x6 # x7 = address of JumpTable[k] ld x7, 0(x7) # temp reg x7 getsJumpTable[k] jalr x1, 0(x7) # jump based on register x7(entrance) Exit:... ... L0:add $s0, $s3, $s4 # k = 0 so f gets i+j jalr x0, 0(x1) # end of this case so go to Exit L1:add $s0, $s1, $s2 # k = 1 so f gets g+h jalr x0, 0(x1) # end of this case so go to Exit L2:sub $s0, $s1, $s2 # k = 2 so f gets g-h jalr x0, 0(x1) # end of this case so go to Exit L3:sub $s0, $s3, $s4 # k = 3 so f gets i-j jalr x0, 0(x1) # end of switch statement代码理解:
-
为什么
slli x7, x25, 3?每条指令都是4B的,下面每个case带2条指令,因此乘以8
-
每个case的最后一句的
jalr x0, 0(x1)是什么作用?跳转回 x1 指令(即Exit),下一条指令没有必要存下来
-
ld x7 0(x7)是为什么?类似于C语言中解引用的过程,可以这么理解。如L0这种label存储的是指令单位置(是一个指向指令的指针),而x6存储的是L0的地址(也就是x6是一个二级指针),因此通过
x7=x6+8*k得到的是存储Lk的地址的寄存器的地址,则此处 ld 指令过后就得到了 Lk的地址
-
-
-
jal和jalr: 无条件跳转指令
-
使用jalr实现Switch
switch ( k ) { case 0 : f = i+ j ; break ; /* k = 0 */ case 1 : f = g + h ; break ; /* k = 1 */ case 2 : f = g -h ; break ; /* k = 2 */ case 3 : f = i-j ; break ; /* k = 3 */ } -
利用 jal 和 jalr 实现函数调用,在下文单独讲,非常重要!
-
Supporting Procedures⚓︎
函数调用的步骤
- Place Parameters in a place where the procedure can access them
- Transfer control to the procedure:jump to
- Acquire the storage resources needed for the procedure
- Perform the desired task Place the result value in a place where the calling program can access it
- Return control to the point of origin
-
Procedure Call Instructions
-
jal 和 jalr 都是无条件跳转
-
jal 即 Jump-and-link :
jal x1,ProcedureAddress[UJ型]- 作为 caller
-
将紧随其后的下一条指令存入 x1 (如果是 x0 就与 goto 指令等价)
-
并跳转至
ProcedureAddress
-
jalr 即 Jump-and-link-register :
jalr x0,0(x1)[I型]- 作为 callee
- 跳转到
0(x1)的位置 - 下一条指令存入 x0 (丢掉不要)
- 因为寄存器的引入可以实现更大的跳转范围
- 可以用作switch功能(实例见前文)
-
UJ 指令的立即数处理

- 可以做到约 1MB 的跳转范围
- 因为省略最低位同样需要 half word 对齐
-
-
参数的功用
- a0 ~ a7(x10 ~ x17) : 传参
- ra/x1 : 传返回地址
-
堆栈
-
栈:高地址到低地址
-
堆:低地址到高地址
-
包括3个参数: push, pop, 堆栈指针(sp)
sp存在两种用法:指向最后一个和指向空的,本课程使用指向最后一个的用法。
以栈为例:
push:
addi sp, sp, -8 sd ..., 0(sp)pop:
ld ..., 0(sp) addi sp, sp, 8-
为了减少入栈出栈,对寄存器进行分类
- t0 ~ t2(x5 ~ x7) 是临时寄存器,函数调用不保存值
- a0 ~a7 用于传参
-
-
样例:阶乘求解
int fact ( int n ){ if ( n < 1 ) return ( 1 ) ; else return ( n * fact ( n -1 ) ) ; }fact: addi sp, sp, -16 # adjust stack for 2 items sd ra, 8(sp) # save the return address:x1 sd a0, 0($sp) # save the argument n:x10(a0) addi t0, a0, -1 # x5 = n - 1 bge t0, zero, L1 # if n >= 1, go to L1(else) addi a0, zero, 1 # return 1 if n <1 addi sp, sp, 16 # Recover sp(Why not recover x1 and x10 ?) jalr zero, 0(ra) # return to caller L1: addi a0, a0, -1 # n >= 1: argument gets ( n -1 ) jal ra, fact # call fact with ( n -1) add t1, a0, zero # move result of fact(n -1) to x6(t1) ld a0, 0(sp) # return from jal: restore argument n ld ra, 8(sp) # restore the return address add sp, sp, 16 # adjust stack pointer to pop 2 items mul a0, a0, t1 # return n*fact ( n -1 ) jalr zero, 0(ra) # return to the caller
代码理解:
-
ra是干什么的?
书上说法是”保存函数调用返回地址“,这里可以举例子帮助理解。
在这段代码中,修改ra的地方除了ld只有jal,前者没啥分析价值,只看
jal ra, fact那句。此处会将jal的后一条指令存入ra,也就是说如果运行了这句话,跳转到fact标签运行,一通操作完之后(肯定入栈和弹栈数量持平),运行jalr zero,0(ra)就会跳回到jal的下一句,即从add t1, a0, zero开始跑。如果放到c里面理解(其实高级语言没有对应的东西),相当于在调用函数之前标记了一下函数后面那句话说是在这里断开开始递归的所以要从这里接着跑。
-
怎么理解a0的双重身份?
a0在传入参数的时候代表 \(n\) ,计算完成的时候才作为 \(n!\) 存在。例如考虑L1的部分。
addi a0, a0, -1是 njal ra, fact和add t1, a0, zero处因为递归调用的完成是存储的 \((n-1)!\) 于是很快就用 t1这个临时变量存起来了ld a0, 0(sp)恢复 a0 为 \(n\)mul a0, a0, t1jalr zero, 0(ra)的位置 a0 终于成为计算结果 \(n!\) -
addi sp, sp, 16 # Recover sp(Why not recover x1 and x10 ?)已经到最底层了,a0不需要往下传,下次使用就是作为 \(0!\) 所以不用改; ra没有变化也不用改
Memory Layout⚓︎
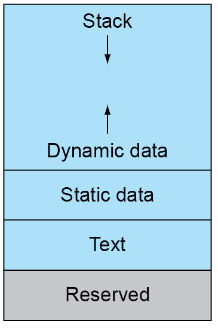
-
Dynamic data : 堆栈,配有 sp
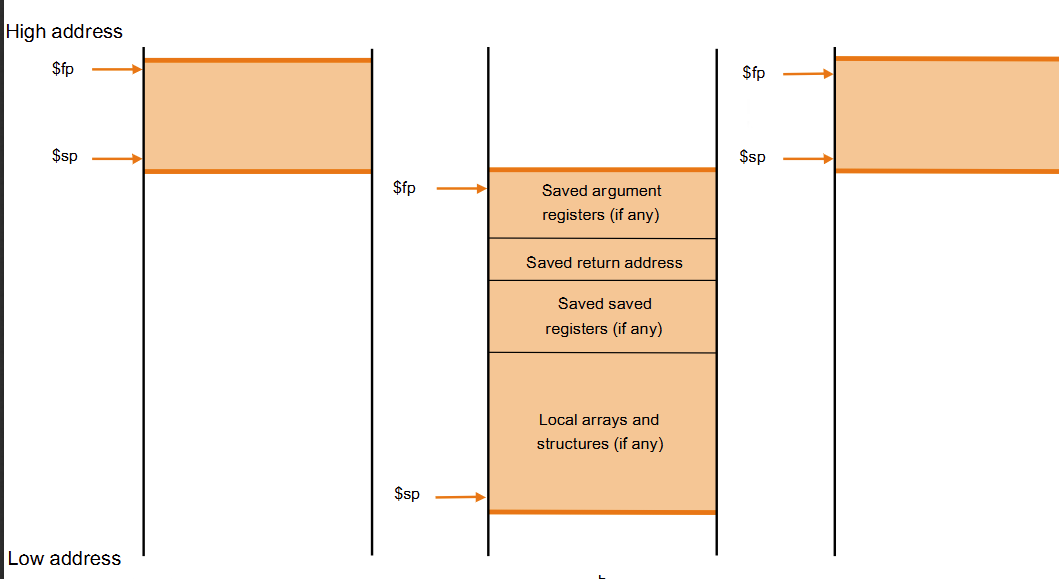
- fp(frame pointer) :指向当前函数压进去的第一个参数的位置(当前进程的起始位置)
- save saved registers : 超过现有32个的寄存器使用(类似于c的malloc)
-
static data : 静态变量(如数组,字符串)、x3 (global pointer)
-
text : 代码
Character Data⚓︎
- Byte-encoded character sets
- ASCII : 128 个字符,其中 33 个是控制字符
- Latin-1 : 在ASCII基础上加了96个可显示字符
- Unicode : 32b
- UTF-8 , UTF 16:可变长度的编码
RISC-V Addressing for 32b Immediate and Address⚓︎
U type指令 lui 有20位立即数,效果如下

则如果要 load 一个 32b 的数可以这样做

Q:为什么是 977 而非 976?
A: 2304的符号位是1,赋值的时候符号位扩展需要补一个1消除掉(也就是值+低一位的值)
Synchronization⚓︎
- Load reserved:
lr.d rd,(rs1)- 从 rs1 读到 rd
- 内存预留
- Store conditional:
sc.d rd,(rs1),rs2- 从 rs2 存到 rs1里面的地址
- 如果该地址未被占用就返回0,反之返回非零值(且不修改)
Other RISC-V Instructions⚓︎
- RV64I & RV32I : 64/32b寄存器
- RV64I中的 addw, subw, addiw, sllw,....是专门处理32b的
- RV32I和RV64I加上后缀表示更多的功能
- M:支持整数乘除法
- A:支持原子操作
- F:支持单精度浮点数
- D:支持双精度浮点数
- C:支持压缩指令(有16b指令)
杂项⚓︎
Basic Block
- 要求:
- 没有分支
- 不会有跳转到中间的情况 ("No branch targets/branch labels, except at beginning")
编译器会对 basic blocks 进行加速